Künstliche Intelligenz "liest" und "versteht" Forschungsartikel
Forscher eines Start-ups trainieren ein neuronales Netz, um chemische Formeln aus Forschungsunterlagen zu erkennen
Anzeigen



Forscher von Syntelly - einem aus Skoltech hervorgegangenen Start-up - der Staatlichen Universität Lomonossow in Moskau und der Sirius-Universität haben eine auf einem neuronalen Netz basierende Lösung für die automatische Erkennung chemischer Formeln auf eingescannten Forschungspapieren entwickelt. Die Studie wurde in Chemistry-Methods, einer wissenschaftlichen Zeitschrift der European Chemical Society, veröffentlicht.

Symbolbild
pixabay.com
Die Menschheit tritt in das Zeitalter der künstlichen Intelligenz ein. Auch die Chemie wird sich durch die modernen Methoden des Deep Learning verändern, die stets große Mengen an qualitativen Daten für das Training neuronaler Netze erfordern.
Die gute Nachricht ist, dass chemische Daten "gut altern". Selbst wenn eine bestimmte Verbindung ursprünglich vor 100 Jahren synthetisiert wurde, sind die Informationen über ihre Struktur, Eigenschaften und Synthesewege auch heute noch relevant. Selbst in unserer Zeit der universellen Digitalisierung kann es durchaus vorkommen, dass ein organischer Chemiker auf eine Originalzeitschrift oder eine Dissertation aus einer Bibliothek zurückgreift - die z. B. in deutscher Sprache bereits Anfang des 20. Jahrhunderts veröffentlicht wurde -, um Informationen über ein schlecht untersuchtes Molekül zu erhalten.

Die schlechte Nachricht ist, dass es keine anerkannte Standardmethode für die Darstellung chemischer Formeln gibt. Chemiker verwenden üblicherweise viele Tricks in Form von Kurzschreibweisen für bekannte chemische Gruppen. Zu den möglichen Abkürzungen für eine tert-Butylgruppe gehören zum Beispiel "tBu", "t-Bu" und "tert-Bu". Erschwerend kommt hinzu, dass Chemiker oft eine Vorlage mit verschiedenen "Platzhaltern" (R1, R2 usw.) verwenden, um auf viele ähnliche Verbindungen zu verweisen, wobei diese Platzhaltersymbole überall definiert sein können: in der Abbildung selbst, im Fließtext des Artikels oder in Ergänzungen. Ganz zu schweigen davon, dass der Zeichenstil in den verschiedenen Zeitschriften variiert und sich mit der Zeit weiterentwickelt, dass die persönlichen Gewohnheiten der Chemiker unterschiedlich sind und dass sich die Konventionen ändern. Das führt dazu, dass selbst ein erfahrener Chemiker manchmal ratlos ist, wenn er versucht, ein "Rätsel" zu lösen, das er in einem Artikel gefunden hat. Für einen Computeralgorithmus scheint die Aufgabe unlösbar zu sein.
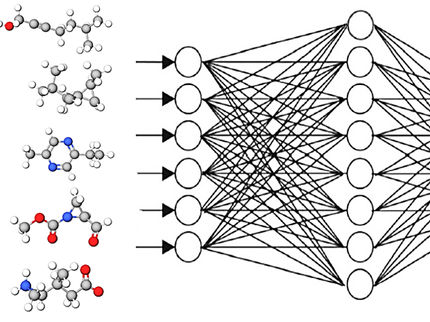
Die Forscher hatten jedoch bereits Erfahrung mit der Lösung ähnlicher Probleme mit Hilfe von Transformer - einem neuronalen Netzwerk, das ursprünglich von Google für die maschinelle Übersetzung vorgeschlagen wurde. Anstatt Text zwischen Sprachen zu übersetzen, nutzte das Team dieses leistungsstarke Werkzeug, um das Bild eines Moleküls oder einer molekularen Vorlage in seine textuelle Darstellung umzuwandeln. Eine solche Darstellung wird Functional-Group-SMILES genannt.
Zur großen Überraschung der Forscher erwies sich das neuronale Netz als in der Lage, fast alles zu lernen, sofern der entsprechende Darstellungsstil in den Trainingsdaten enthalten war. Allerdings benötigt Transformer zum Trainieren Dutzende von Millionen von Beispielen, und so viele chemische Formeln aus Forschungsarbeiten von Hand zu sammeln, ist unmöglich. Daher wählte das Team einen anderen Ansatz und erstellte einen Datengenerator, der Beispiele für molekulare Vorlagen erzeugt, indem er zufällig ausgewählte Molekülfragmente und Darstellungsstile kombiniert.
"Unsere Studie ist ein gutes Beispiel für den laufenden Paradigmenwechsel bei der optischen Erkennung von chemischen Strukturen. Während sich frühere Forschungen auf die Erkennung von Molekülstrukturen an sich konzentrierten, können wir uns jetzt, da wir über die einzigartigen Fähigkeiten von Transformer und ähnlichen Netzwerken verfügen, stattdessen der Schaffung künstlicher Mustergeneratoren widmen, die die meisten der existierenden Darstellungsstile von Molekülvorlagen imitieren würden. Unser Algorithmus kombiniert Moleküle, funktionelle Gruppen, Schriftarten, Stile, sogar Druckfehler, er fügt Bits zusätzlicher Moleküle, abstrakte Fragmente usw. ein. Selbst für einen Chemiker ist es schwer zu erkennen, ob das Molekül direkt aus einem echten Papier oder aus dem Generator stammt", so der Hauptautor der Studie, Sergey Sosnin, der CEO von Syntelly, einem bei Skoltech gegründeten Startup-Unternehmen.
Die Autoren der Studie hoffen, dass ihre Methode ein wichtiger Schritt auf dem Weg zu einer künstlichen Intelligenz ist, die in der Lage wäre, Forschungspapiere in dem Maße zu "lesen" und zu "verstehen", wie es ein hochqualifizierter Chemiker tun würde.
Hinweis: Dieser Artikel wurde mit einem Computersystem ohne menschlichen Eingriff übersetzt. LUMITOS bietet diese automatischen Übersetzungen an, um eine größere Bandbreite an aktuellen Nachrichten zu präsentieren. Da dieser Artikel mit automatischer Übersetzung übersetzt wurde, ist es möglich, dass er Fehler im Vokabular, in der Syntax oder in der Grammatik enthält. Den ursprünglichen Artikel in Englisch finden Sie hier.
Originalveröffentlichung


Weitere News aus dem Ressort Wissenschaft





















Meistgelesene News






Weitere News von unseren anderen Portalen



























Da tut sich was in der Chemie-Branche …
So sieht echter Pioniergeist aus: Jede Menge innovative Start-ups bringen frische Ideen, Herzblut und Unternehmergeist auf, um die Welt von morgen zum Positiven zu verändern. Tauchen Sie ein in die Welt dieser Jungunternehmen und nutzen Sie die Möglichkeit zur Kontaktaufnahme mit den Gründern.